Crystalにおける並列処理


Crystalは、並列処理を第一級オブジェクトとして扱うための大きな一歩を踏み出しました。簡単に言うと、実行時にワーカースレッドの数を設定することができ、新しく生成されたファイバーは、それらのいずれかで実行されるようにスケジュールされます。チャネルとselectはシームレスに動作します。ワーカー間でメモリを共有することはできますが、状態の一貫性を保つために、何らかの同期処理が必要になるでしょう。
この作業には多大な労力を要しましたが、リファクタリング、設計に関する議論、並列処理に取り組む試みのおかげで、間違いなく負担が軽減されました。マージされたかどうかに関わらず、過去のすべての作業は、考え方を再確認するための参考資料となりました。
この記事では、新しい機能の説明、設計、直面した課題、そして今後のステップについて、すべて網羅しようとします。すぐに使い始めたい場合は、最初のセクションだけで十分です。最終的な目標は、利用可能なすべてのCPU能力を使用できるようにすることですが、言語を大きく変更することはありません。そのため、この記事の後半では、いくつかの課題と未解決の作業について触れています。
使用方法:クイックガイド
これらの機能を利用するには、`preview_mt`サポートを有効にしてプログラムをビルドする必要があります。最終的にはこれがデフォルトになりますが、今のところオプトインする必要があります。
このドキュメントで後述するように、データはワーカー間で共有できますが、データ競合を回避するのはユーザーの責任です。一部の標準ライブラリは、安全でない動作を回避するために、まだ rework する必要があります。
- `-Dpreview_mt`でプログラムをビルドします。 `crystal build -Dpreview_mt main.cr`
- `. /main`を実行します。(オプションで、`CRYSTAL_WORKERS=4`のようにワーカースレッドの数を指定します。デフォルトは`4`です)
APIの最初のトップレベルの変更点は、新しいファイバーを生成する際に、同じワーカースレッドで実行するかどうかを指定できるようになったことです。
spawn same_thread: true do
# ...
end
これは、特定のスレッドローカル状態を確保する必要がある場合、または呼び出し元が同じスレッドであることを確認する必要がある場合に特に役立ちます。
初期ベンチマーク
このセクションに示されているベンチマークは、`c5.2xlarge` EC2インスタンスで`manastech/benchy`を使用して`bcardiff/crystal-benchmarks`から生成されました。
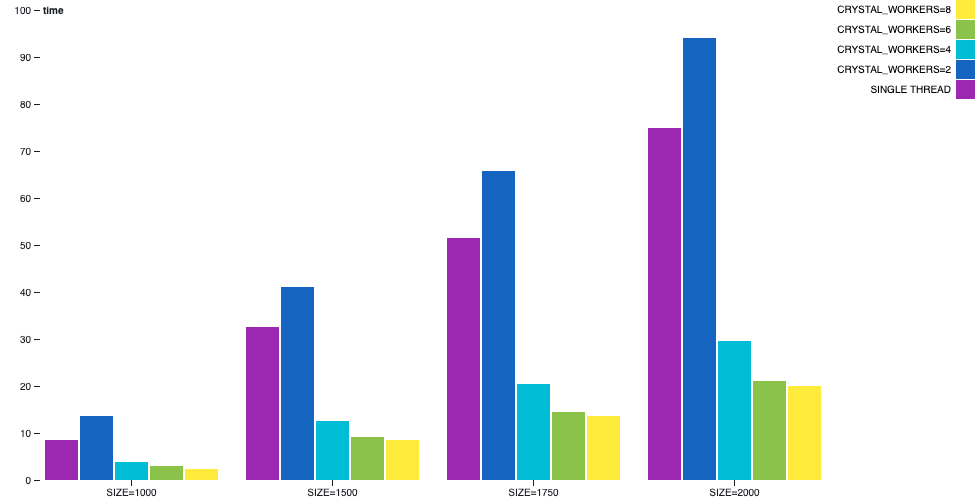
行列乗算
行列の乗算は並列化できるプロセスであり、スケーリングも良好です。また、I/Oがないため、CPUバウンドのシナリオを分析するのに適した例です。
この例では、マルチスレッドでコンパイルすると、1つのワーカースレッドが各座標の結果の完了を委任して待機し、他のワーカースレッドは計算要求を取得して処理します。
シングルスレッドと実際に計算を行う1つのワーカースレッドを比較すると、ユーザー時間の増加が見られます。マルチスレッドはシングルスレッドに比べてブックキーピングと同期処理のオーバーヘッドが大きいため、遅くなります。しかし、ワーカーが追加されるとすぐに、パフォーマンスが大幅に向上します。このシナリオでは、すべてのスレッドが最高速度で実行されることを期待してください。
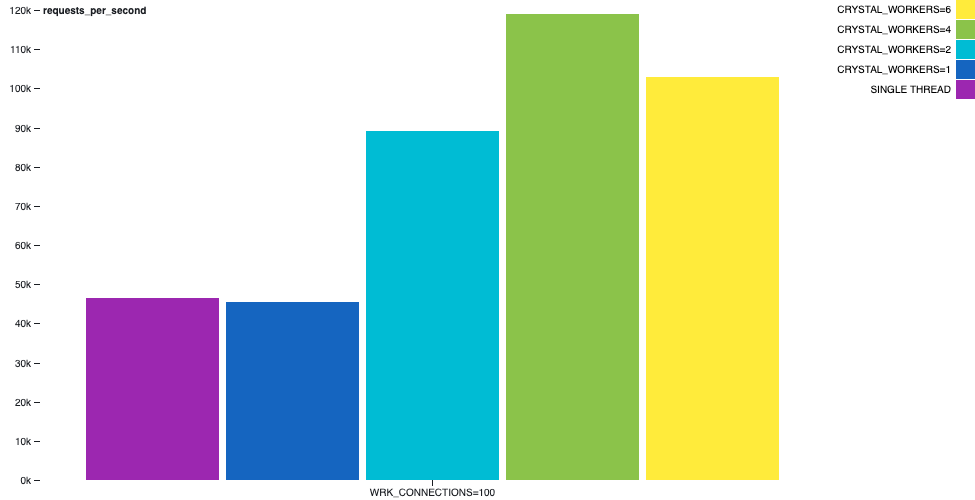
Hello World HTTPサーバー
よく登場する合成ベンチマークは、`GET /`リクエストに対して`hello world`を返すHTTPサーバーです。各リクエストに対応して短いレスポンスを作成する際には、レスポンスの作成中にI/O操作が発生するため、コンテキストスイッチは通常不要です。
たとえば、次のチャートでは、`hello-world-http-server`サンプルの動作を示しています。同じマシン上で`wrk`ツールを実行し、30秒間2スレッドと100接続を使用しました。スループットの興味深い増加が見られます。
チャネルによる素数生成
`channel-primes`の例では、複数のチャネルを一種のシーケンスで連結することにより、素数が生成されます。n番目の素数は、出力されるまでにn個のチャネルを通過します。これは、アルゴリズムを明らかな方法でバランスさせることができず、多くの通信が発生するため、病的なシナリオと見なすことができます。
この例では、マルチスレッドが万能薬ではないことがわかります。シングルスレッドの方がマルチスレッドよりも outperform します。
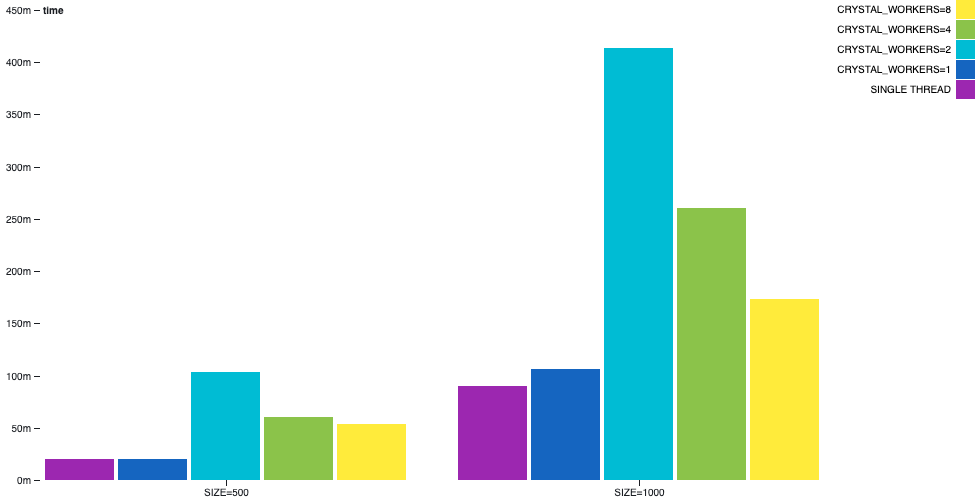
ワーカーの数によっては wall time の差はそれほど目立ちませんが、CPU時間の差は大きくなります。
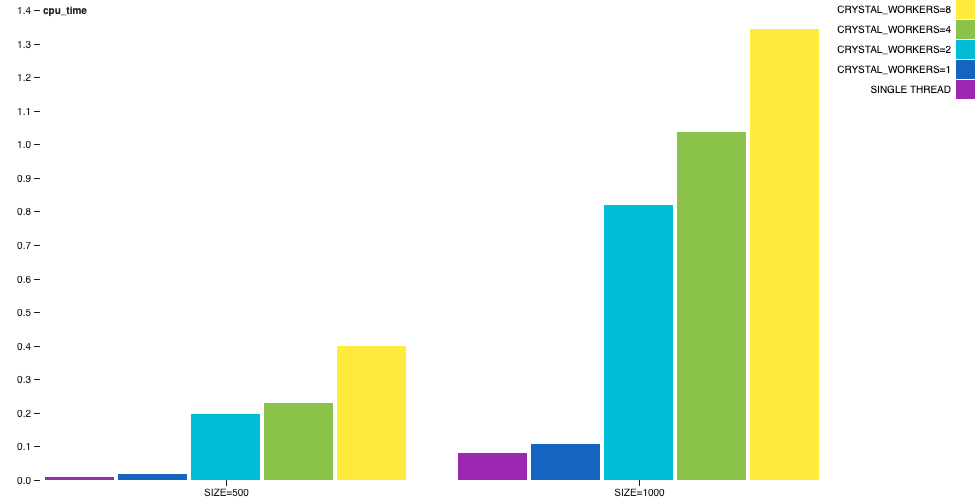
詳細な説明
私たちは、言語の性質を変えることなく、並列処理のサポートを提供したいと考えました。プログラマーは、実行中のファイバーの単位で考え、データにアクセスし、ほとんどの場合、コードがどのスレッドで実行されているかを気にせずに済むようにする必要があります。これは、スレッドとファイバー間でデータを共有することを意味します。そして、スレッドをできるだけユーザーから隠しておくことです。
その過程で、ランタイムのいくつかのコアとなる側面の内部実装と設計をいくつか変更する必要がありました。また、コンパイラ自体にもいくつかの問題を修正する必要がありました。一部は抽出され、個別に提出されました。そして最後に、言語自体の健全性と安全性に関するいくつかの問題は、現在、マルチスレッドを有効にすることで影響を受けています。
シングルスレッドモードでは、1つのイベントループを持つ1つのワーカースレッドが存在します。イベントループは、I/Oの完了を待機しているファイバーを再開する役割を担います。マルチスレッドモードでは、各ワーカースレッドは独自のイベントループを持ち、基本的に以前のメカニズムの複数のインスタンスとして動作しますが、いくつかの追加機能があります。
各ワーカースレッド間のメモリは共有することができ、変更可能です。これは、多くの頭痛の種となるでしょう。ロックを使用してアクセスを同期するか、同時アクセスを処理できる適切なデータ構造を使用する必要があります。
チャネルは、APIを変更することなく、異なるワーカースレッド間でメッセージを送受信することができ、ファイバー間の通信と同期のための主要な方法として使用されるべきです。
`select`ステートメントには、特別な注意が必要でした。`select`は、複数のチャネルに多くの受信者と送信者を挿入します。これらのいずれかが`select`の条件を満たすとすぐに、残りの受信者と送信者は無視される必要があります。このため、ファイバーが`select`操作で送信者または受信者としてエンキューされると、`SelectContext`が作成され、`select`全体の状態が追跡されます。`Channel#dequeue_receiver`と`Channel#dequeue_sender`には、`select`がすでに完了している場合にそれらをスキップするロジックがあります。
プログラムが起動するとすぐに、環境変数`CRYSTAL_WORKERS`の値に基づいてワーカースレッドの初期化が行われます。各ワーカースレッドは、`runnables`キューを持つ独自の`Scheduler`を持ちます。
マルチスレッドモードであっても、ワーカーが初期化されるまでの短い時間があり、プログラムは1つのワーカーだけで動作します。これは、いくつかの定数とクラス変数を初期化している間に発生します。
Scheduler を介して、マルチスレッドモードでの状態を保護するためのいくつかの条件があります。キューは独立していますが、ワーカーは新しいファイバーをディスパッチするために互いに通信する必要があります。ターゲットワーカーがスリープしていない場合、新しいファイバーは直接キューに入れられます(キューは現在のワーカーからアクセスされるため、同期する必要があることに注意してください)。ターゲットワーカーがスリープしている場合、パイプを使用して実行する新しいファイバーを送信し、イベントループを介してワーカーをウェイクアップします。パイプは、スケジューラー内の各ワーカースレッドに対して作成されます。これは、Scheduler#run_loop、Scheduler#send_fiber、Scheduler#enqueue で処理されます。
どのワーカースレッドがファイバーを実行するかは、ラウンドロビン方式で決定されます。このポリシーは、将来、ワーカーごとの負荷メトリックによって変更される可能性があります。しかし、私たちは考えられる最も単純なロジックを選択しました。これは、必要に応じて将来の改善のベースラインとして機能します。
スケジューリングに関して、物事をできるだけシンプルに保つために、ファイバーがワーカースレッドで実行を開始すると、別のスレッドに移行することはありません。もちろん、サスペンドして再開することはできます。しかし、私たちはファイバースティーリングなしで開始することを明示的に選択しました。
APIの変更
マルチスレッドプログラムのコンパイル
マルチスレッドをサポートするプログラムのコンパイルは、今のところ preview_mt フラグの背後にあります。また、Crystal 0.31.0(まだリリースされていません)またはマスターのローカルビルドを使用していることを確認してください。
$ crystal --version
Crystal 0.31.0
$ crystal build -Dpreview_mt main.cr -o main
実行時にワーカースレッドの数を設定する
ワーカースレッドの数は、CRYSTAL_WORKERS 環境変数を介してカスタマイズできます。デフォルトは 4 です。
$ ./main # will use 4 workers
$ CRYSTAL_WORKERS=4 ./main
$ CRYSTAL_WORKERS=8 ./main
spawn
spawn で作成された新しいファイバーは、デフォルトでは、どのワーカースレッドでも自由に実行できます。同じファイバーを現在のワーカースレッドで実行する必要がある場合は、spawn(same_thread: true) { ... } を使用できます。これは、スレッドローカルストレージが使用される一部のCライブラリで役立ちます。
Mutex
Mutex は、ファイバー間で機能するロックを要求する方法です。実際のAPIの変更はありませんが、マルチスレッドモードでも動作が維持されることに注意してください。pthreadのラッパーである内部の Thread::Mutex の存在を知っている人もいるかもしれません。Thread::Mutex を直接使用することは、自分が何をしているのか、なぜそうしているのかを本当に理解していない限り、お勧めしません。トップレベルの Mutex を使用してください。
Channel
クローズされたチャネルの動作が見直されました。これからは、シングルスレッドまたはマルチスレッドプログラムのいずれかで、既に送信されたメッセージが消費されるまで、クローズされたチャネルで受信アクションを実行できます。そうでない場合、キューとチャネルの状態の同期が必要になるため、これは理にかなっています。確かに、チャネルが閉じられると、新しいメッセージを送信することはできません。
Channel(T) は、バッファされていないチャネルとバッファされたチャネルの両方を表すようになりました。初期化するときは、それぞれ Channel(T).new または Channel(T).new(capacity) を使用してください。
Fork
forkとマルチスレッドプログラムの混在は問題があります。そのシナリオの問題を説明する参考文献がいくつかあります
fork メソッドはマルチスレッドでは使用できず、おそらくパブリックAPIとしては廃止されます。標準ライブラリはまだサブプロセスを開始するためにforkを必要としていますが、forkの後にexecが実行されるため、このシナリオは安全です。
forkが必要になる可能性のある別のシナリオは、プロセスをデーモン化することですが、その話はもう少し進化する必要があります。
Locks
Crystal::SpinLock にはスピンロックの内部実装があり、シングルスレッドでコンパイルするとNull-Lockとして動作します。Crystal::RWLock にはRW-Lockの内部実装もあります。
これらのロックはランタイムで使用され、パブリックAPIとして使用されることは想定されていません。しかし、それらの存在について知っておくのは良いことです。
課題
マルチスレッドサポートの現在の設計に到達するまでに、何度か反復を行いました。それらのいくつかはパフォーマンス上の理由から破棄されましたが、本質とAPIは現在のものと似ています。他のアイデアは、プロセス間に何らかのレベルの分離を持たせるように促しました。明確な境界を設定することで、ロックと同期を削減するのが簡単になります。Rustの影響を部分的に受けたこれらの設計のいくつかは、プロセス間で共有可能および共有不可能な型と、別のプロセスに送信できるかどうかを模倣する新しいタイプのクロージャにつながったでしょう。他のドラフトのアイデアもありましたが、最終的には、十分なパフォーマンスを持つ実装に到達したため、共有データにアクセスするファイバーを実行するというプログラムの現在の性質により合致するものに落ち着きました。ランタイムを動作させ続けるための実装の詳細に加えて、言語セマンティクスに関するいくつかのストーリーはまだ進化する必要がありますが、共有状態を同期する限り、安全であるはずです。
チャネルのライフサイクルが少し変更されました。簡単に言うと、ファイバーがチャネルを待機しているとき、ファイバーはもはや*実行可能*ではありません。しかし、今では、待機中のチャネル操作には、メッセージを受信する必要がある指定されたメモリ スロットが既にあります。そのチャネルを介してメッセージが送信される場合、指定されたメモリ スロット(共有メモリ FTW)に格納されます.最後に、一時停止されていたファイバーは実行可能として再スケジュールされ、最初の操作はメッセージを読み取って返すことです。これは、Channel#receive_impl メソッドで見ることができます。待機中のファイバーがスリープ状態のスレッド(実行可能なファイバーがない)にあった場合、新しいファイバーの配信に使用されたのと同じパイプを使用して、スリープ状態のスレッドにファイバーをキューに入れ、ウェイクアップします。
チャネルとselectの変更を実装している間、同じチャネルで送受信を実行するselectなど、いくつかのコーナーケースに対処する必要がありました。また、チャネルの表現の不変条件を再考することになりました。Goのチャネルと同様の制約を持つ設計に到達したとき、それは私たちにとって大きな意味を持ちました。
(..) c.sendqとc.recvqの少なくとも一方は空です。selectステートメントを使用して送受信の両方で単一のゴルーチンがブロックされているバッファされていないチャネルの場合を除きます(…) source
上記のチャネルメカニズムは、イベントループの設計方法 때문에 機能します。各ワーカースレッドには、Scheduler#run_loop に独自のイベントループがあり、実行可能キューからファイバーをポップするか、空の場合は、ファイバーがそのワーカースレッドのパイプを介して送信されるまで待機します。このメカニズムはチャネルだけでなく、I/O全般に適用されます。I/O操作を待機する場合、現在のファイバーは、IO::Evented#evented_close でイベントが完了するまで、IO内部キューのリーダーまたはライターキューで保留になります。その間、ワーカースレッドは他のファイバーを実行し続けるか、アイドル状態になる可能性があります。I/Oを実行していたファイバーは、ビジー状態またはアイドル状態のスレッドとの通信ロジックを処理する Scheduler.enqueue によって復元されます。
libeventとの統合のために、ワーカースレッドごとに1つの Crystal::Event::Base を初期化する必要もありました。IO をワーカー間で直接共有できるようにしたいと考えており、それぞれが LibEvent2::Event をラップする Crystal::Event への参照を必要とします。Crystal::Event は、単一の Crystal::Event::Base にバインドされています。解決策は、各 IO(IO::Evented 経由)が、スレッドごとにインデックス付けされたハッシュにイベントと待機中のファイバーを持っていることでした。スレッドでイベントが完了すると、そのスレッドの待機中のファイバーのみに通知できます。
@[ThreadLocal] アノテーションは広く使用されておらず、OpenBSDやその他のプラットフォームでいくつかの既知の問題があります。その動作を模倣するために内部の Crystal::ThreadLocalValue(T) クラスが必要であり、IO の基礎となる実装で使用されます.
定数とクラス変数は、一部のシナリオでは遅延初期化されます。最終的にはそれを変更したいと考えていますが、今のところ初期化中にロックが必要です。そのロックをどこに置くかは課題のままです。定数にはできないからです。コンパイラによく知られている内部関数である __crystal_once_init と __crystal_once の両方が導入され、定数とクラス変数の遅延初期化関数で使用されます。
開始スケジューリングアルゴリズムは、ファイバースティーリングのないラウンドロビンであると述べました。各ワーカーの負荷のメトリックを持つことを試みましたが、ワーカーは互いに通信して新しいファイバーを委任できるため、負荷を計算するには、同期する必要がある状態が増えます。その上、現在の実装では、通信に使用されるパイプにファイバーへの参照があるため、@runnables キューサイズは正確なメトリックではありません.
GCは過去にマルチスレッドをサポートしていましたが、パフォーマンスは十分ではありませんでした。最終的に、コンテキストスイッチ(リーダー)とGCコレクション(ライター)の間にRW-Lockを実装しました。RW-Lockの実装は Concurrency Kit に触発されており、Mutexを使用していません。
驚くことではありませんが、注目すべき点として、マルチスレッドサポートでビルドされたコンパイラは、まだコアを活用していません。 これまで、コンパイラはデバッグモードでプログラムをビルドする際にforkを使用していました。そのため、前述の問題により、マルチスレッドではコンパイラオプション--threadsは無視されます。これは、将来サポートされず、他の構文で書き直す必要があるforkのユースケースです。
シングルスレッドモードは引き続き利用できるようにすることを目指す予定です。マルチスレッドが常に優れているとは限らないからです。これはシャードの領域に影響を与える可能性があります。 シャードが明示的にどちらかのモードでのみ動作するように制約されるかどうか、またそうである場合、それをどのように記述するかはまだ不明です。
メモリ表現の一部と、コンパイラがそれらを操作するために出力する低レベルの命令は、マルチスレッドモードとうまく連携しません。少なくとも、言語の健全性を保つためにセグメンテーション違反を防ぐ必要があります。繰り返しになりますが、共有データへのアクセスが同期されている限り問題ありませんが、これはプログラマーが責任を負い、言語が十分に安全ではないことを意味します。以下のセクションでは、いくつかのシナリオとそれらを解決するための現在の状態について説明します。
言語の型安全性
データ構造に異なるスレッドから同時にアクセスする場合、同期がないと、命令がインターリーブされ、予期しない結果になる可能性があります。この問題は新しいものではなく、多くの言語が悩まされています。配列のようなデータ構造を扱う場合、最悪のシナリオでは、パブリックAPIの周囲で何らかの同期を検討できます。しかし、時には、矛盾した状態がより微妙な方法で現れることがあります。
言語がアトミックに書き込むことができるメモリ量よりも大きい値型を許可する場合、いくつかの奇妙なことに気付くかもしれません。スレッドが常に値{0, false}を設定し、2番目のスレッドが値{1, true}を設定し、3番目のスレッドが値を読み取る共有Tuple(Int32, Bool)があるとします。命令のインターリーブにより、最後のスレッドは時々値{1, false}と{0, true}を見つけます。ここでは安全ではないことは何も起こりません。これらはTuple(Int32, Bool)の可能な値ですが、書き込まれたことのない値を読み取ることができるのは奇妙です。任意のサイズの値型を持つ多くの言語は、通常、この問題を示します。
Crystalでは、値型と参照型の間の共用体は、型IDと値自体のタプルとして表されます。Int32 | AClassの共用体は、nil値を持たないことが保証されています。しかし、インターリーブにより、nilの表現が現れる可能性があり、ヌルポインタ例外(この場合はセグメンテーション違反)が発生します。
配列に関しては、同様のことが起こる可能性があります。参照型の配列(値としてnilなし)は、あるスレッドが最後の項目を逆参照している間に別のスレッドが項目を削除する可能性があるため、セグメンテーション違反につながる可能性があります。項目を削除するとメモリにゼロが書き込まれるため、GCはメモリを要求できますが、ゼロアドレスは逆参照できる値ではありません。
共用体のコード生成を異なる方法で実行するためのアイデアがいくつかあります。そして、そのうちの1つはすでに機能していますが、プログラムのメモリフットプリントとバイナリサイズの両方を増やすという犠牲を払っています。他の選択肢を検討し、比較してから1つを選択したいと思います。今のところ、クラス変数、インスタンス変数、定数、またはクロージャ変数に現れる可能性のある共有共用体は安全ではないことに注意する必要があります(ただし、安全になります)。
配列の安全でない動作に対処するには、共有可変データ構造で必要となる可能性のあるさまざまなアプローチと保証に関して議論する必要があります。最も強力な保証は、そのアクセスをシリアル化することと同様です(すべてのメソッドの周囲にMutexがあると考えてください)。より弱い保証は、アクセスはシリアル化されないが、常に一貫した状態につながることです(すべての呼び出しは一貫した最終状態を生成しますが、どれが使用されるかは保証されません)。そして最後に、状態のインターリーブ操作を許可するという無効な保証です。.
保証レベルが選択された後、そのためのアルゴリズムを見つける必要があります。これまでのところ、私たちはより弱い実装で回避策を講じてきました。しかし、GCとの統合が必要です。その統合は現在ボトルネックとなっており、まだ検討中です。今のところ、手動で同期しない限り、共有配列は安全ではないことに注意する必要があります。
配列で見つかった課題は、ポインタのすべての操作に現れます。ポインタは安全ではなく、配列のコードを操作している間、レビュープロセスをガイドするために言語に安全/安全でないセクションを用意したいと強く思いました。Dequeなど、同じ問題を抱えている他の構造体があります。
次のステップ
マルチスレッドモードが言語の第一級市民であると主張できるようになるまでには、まだいくつかの作業が残っていますが、ランタイムでこのアップデートを行うことは間違いなく大きな前進です。フィードバックを収集し、反復を続け、次のいくつかのリリースでpreview_mtからpreviewを削除できるようにしたいと考えています。
私たちは84codesと他のすべてのスポンサーの継続的なサポートのおかげで、これらすべてを行うことができました。この開発ペースを維持できるように、寄付を通じてサポートを維持することが非常に重要です。OpenCollectiveとBountysourceは、そのための2つの利用可能なチャネルです。直接スポンサーになりたい場合、またはCrystalをサポートする他の方法を見つける場合は、crystal@manas.techに連絡してください。事前に感謝いたします!